전 글에서는 공공데이터 API를 사용해서 영화 데이터를 가져왔다.
이번에는 전 글의 마지막에서 말했던 '이 영화가 이러이러한 장면과 묘사 때문에 15세 등급이다.' 와 같은 정보, 즉 영화의 서술적 내용기술(서술적 묘사) 정보를 가져오자.
영화의 서술적 내용기술은 API에서 제공하고 있지 않지만, ors홈페이지의 등급자료조회 서비스를 사용하면 얻을 수 있다.
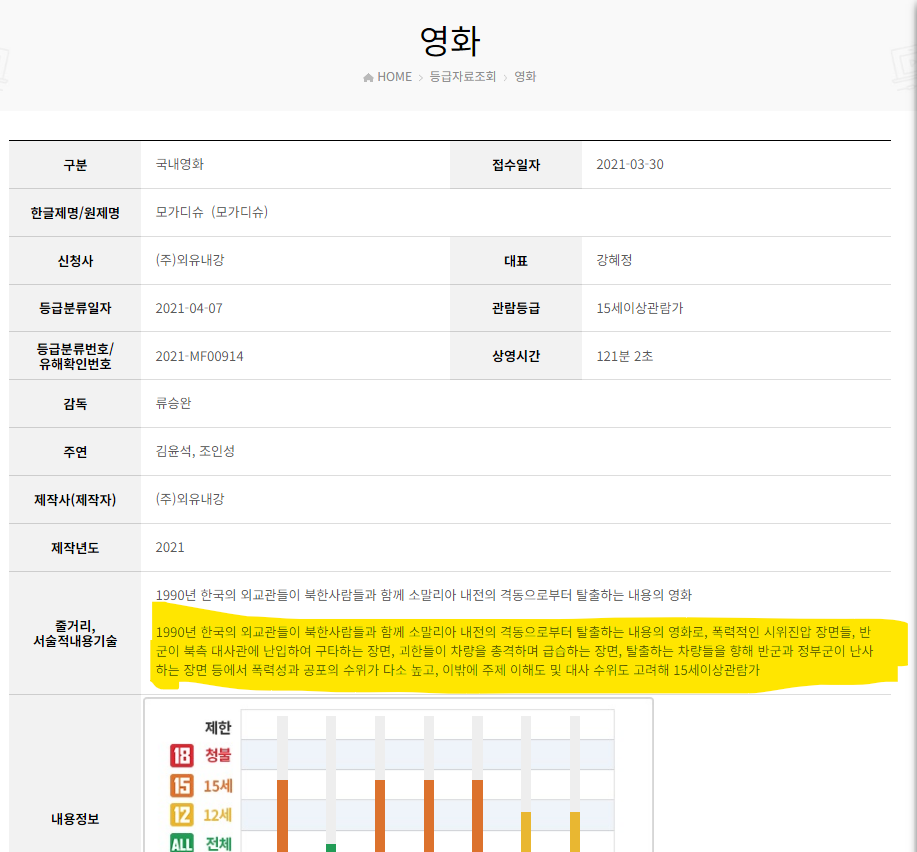
위의 서술적 내용기술은 ors의 등급자료조회로만 얻을 수 있다.
하지만 별도의 API를 제공하고 있지 않기에, 홈페이지에서 직접 정보를 가져와야한다.
서술적 내용기술 정보를 얻는 방법은 다음과 같다.
- 공공데이터의 API 호출로 얻은 각 영화 데이터들의 제목과 등급번호를 페이지의 검색칸에 입력하고, 검색버튼을 누른다.
- 검색결과를 클릭한다. (제목과 등급번호가 동시에 같은 영화는 존재하지 않으므로, 검색 결과는 무조건 1개만 나온다.)
- 검색 결과 클릭으로 나오는 페이지에서 서술적 내용기술 부분의 텍스트를 가져온다.
위의 과정을 수작업으로 할 수는 없으므로, selenium을 사용하여 자동화 한다.

등급자료조회 검색 페이지의 url로 driver.get()함수를 실행해서 정보를 가져올 준비를 한다.
# for local
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
chrome_options.add_argument('headless')
url = 'http://ors.kmrb.or.kr/rating/inquiry_mv_list.do'
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)

검색 페이지의 html코드에서 클릭해야 할 버튼이나 가져와야 할 정보들의 xpath를 얻어 driver.findelement() 함수의 인자로 넘겨줘야 한다.
아래의 함수는 공공데이터 API의 영화데이터를 dict type으로 넣으면 서술적 내용기술 정보를 selenium을 사용해 얻은 후, dict에 추가해서 리턴하는 함수이다.
def get_descriptive_content(dic):
global driver
driver.find_element(By.NAME, 'rt_no').clear()
driver.find_element(By.NAME, 'mv_use_title').clear()
driver.find_element(By.NAME, 'rt_no').send_keys(dic['rtNo'])
driver.find_element(By.NAME, 'mv_use_title').send_keys(dic['useTitle'])
driver.find_element(By.CLASS_NAME, 'btn_bottom_search').click()
driver.find_element(By.XPATH, '/html/body/section[2]/form/div/div[3]/table/tbody/tr/td[2]/a').click()
xpaths = driver.find_elements(By.XPATH, '/html/body/section[2]/div/table/tbody/tr')
for xpath in xpaths:
if xpath.text.split('\n')[0] == '줄거리,':
if len(xpath.text.split('\n')) < 3:
driver.find_element(By.XPATH, '/html/body/section[2]/div/div/input').click()
dic['descriptive_content'] = ''
else:
text = xpath.text.split('\n')[-1]
driver.find_element(By.XPATH, '/html/body/section[2]/div/div/input').click()
dic['descriptive_content'] = text
return dic
# 만약 다른페이지로 넘어가서 descriptive_content를 가져오지 못했을 경우에는 원래 페이지로 돌아간다.
# (성인 영상물인 경우 인증페이지로 넘어감. get_items()의 필터로 못 걸러 냈을 때를 대비하는 코드)
global count_18
count_18 += 1
driver.get('http://ors.kmrb.or.kr/rating/inquiry_mv_list.do')
return {}
(len(xpath.text.split('\n')) < 3: 조건문 => 2009년 이전 데이터는 서술적 내용기술 정보가 존재하지 않아서 예외처리한거)
이렇게 해서 공공데이터 API와 ors의 서술적 내용기술 정보를 합친 영화 데이터를 얻을 수 있다.
'프로젝트 > 아이의 영화' 카테고리의 다른 글
| 아이의 영화 앱 만들기#5-자동화 (Google Cloud Run) (0) | 2023.10.24 |
|---|---|
| 아이의 영화 앱 만들기#4-데이터 저장(Firestore) (0) | 2023.10.18 |
| 아이의 영화 개인정보처리방침 (0) | 2023.10.14 |
| 아이의 영화 앱 만들기#3-영화 데이터(1) (0) | 2023.09.18 |
| 아이의 영화 앱 만들기#2-앱 기능 및 구조 (0) | 2023.09.18 |